Routh-Hurwitz Theorem
Let's say we have some polynomial @@p(z)@@ with real coefficients.1 The idea underlying both Eve's theorem and the Routh-Hurwitz theorem is to observe what happens as we sweep @@z@@ from bottom to top along the imaginary axis. Starting with Routh-Hurwitz, it asks us to keep track of the angle that the output of @@p@@ makes with the origin as we sweep. The theorem says that that angle will move 180° counterclockwise overall for each root in the left half of the complex plane that does not have a corresponding root in the right half.2 More formally, assume that @@p@@ has @@n_L@@ roots with real part less than zero and @@n_R@@ greater than zero. Then, the "winding number" about the origin of the path @@\gamma(t) = p(it)@@, where @@t@@ ranges from @@-\infty@@ to @@+\infty@@, is @@\frac{1}{2}(n_L - n_R)@@.3 (We're assuming no roots lie on the imaginary axis.)
Informal Proof
This fact can be intuited by observing what happens when considering a single root @@r@@. There are two cases; for now, suppose @@\Re[r] < 0@@. When @@t@@ is a large negative number, the arrow pointing from @@r@@ to @@it@@ is directed almost straight down, giving an angle of -90° or @@-\frac{\pi}{2}@@. As @@t@@ increases, eventually @@it@@ comes abreast of @@r@@, and @@\Im[it] = \Im[r]@@. The point @@it@@ passes to the right of @@r@@ since its real part (zero) is greater than that of @@r@@, so the angle at this point is @@0@@. Furthermore, the angle monotonically increased from @@-\frac{\pi}{2}@@ up to @@0@@ to get to this point. Finally, as @@t@@ becomes a large positive number, the angle smoothly increases up to @@\frac{\pi}{2}@@, as the arrow from @@r@@ to @@it@@ points almost straight up. Overall, @@r@@ induces a change in angle of @@+\pi@@. This same analysis can be done in the case where @@\Re[r] > 0@@. In that case, the angle sweeps from @@\frac{3\pi}{2}@@ to @@\pi@@ to @@\frac{\pi}{2}@@. The initial and final angles are the same (modulo @@2\pi@@), but the change in angle is @@-\pi@@ instead since we pass to the left of @@r@@.

Effectively, the previous paragraph considered monomials of the form @@z - r@@. But remember, a general polynomial1 can be written as a product of these monomials. Let's say @@p(z) = \prod_{a=1}^n (z - r_a)@@. Angles add when multiplying complex numbers, so the total change in angle over the path @@\gamma(t) = p(it)@@ is just the sum of the changes in angles for each @@\gamma_a(t) = it - r_a@@. From the previous paragraph, we know that
%% \Delta \arg \left[ \gamma_a \right] = \begin{cases} +\pi & \text{if } \Re[r_a] < 0 \nl -\pi & \text{if } \Re[r_a] > 0 \nl \end{cases}, %%
so
%% \begin{align*} \Delta \arg \left[ \gamma \right] &= \sum_{a=1}^n \begin{cases} +\pi & \text{if } \Re[r_a] < 0 \nl -\pi & \text{if } \Re[r_a] > 0 \nl \end{cases} \nl &= \pi \cdot n_L - \pi \cdot n_R \nl &= \pi \cdot (n_L - n_R). \end{align*} %%
The winding number is just that divided by @@2\pi@@.
Formal Proof
The previous argument is a bit hand-wavy, but it seems to be borne out in the algebra. If we want to be more formal, we compute
%% \begin{align*} \Delta \arg \left[ \gamma \right] &= \Im \left[ \int_\gamma \frac{1}{z} dz \right] \nl &= \Im \left[ \int_{-\infty}^{\infty} \frac{i \cdot p^\prime(it)}{p(it)} dt \right]. \end{align*} %%
If
%% p(z) = \prod_{a=1}^n (z - r_a), %%
then
%% p^\prime(z) = \sum_{a=1}^n \prod_{b \neq a} (z - r_b), %%
so
%% \begin{align*} \frac{p^\prime(z)}{p(z)} &= \frac{\sum_{a=1}^n \prod_{b \neq a} (z - r_b)}{\prod_{b=1}^n (z - r_b)} \nl &= \sum_{a=1}^n \frac{\prod_{b \neq a} (z - r_b)}{\prod_{b=1}^n (z - r_b)} \nl &= \sum_{a=1}^n \frac{1}{z - r_a}. \end{align*} %%
Substituting gives
%% \begin{align*} \Delta \arg \left[ \gamma \right] &= \Im \left[ \int_{-\infty}^{\infty} i \cdot \sum_{a=1}^n \frac{1}{it - r_a} dt \right] \nl &= \sum_{a=1}^n \Im \left[ \int_{-\infty}^{\infty} \frac{i}{it - r_a} dt \right] \nl &= \sum_{a=1}^n \Delta \arg \left[ \gamma_a \right]. \end{align*} %%
Now, here we have the same structure we have in the informal proof. We have a sum over terms which each involve a single root of @@p@@. And it would seem that each term is just the change in angle about the origin of the path @@\gamma_a(t) = it-r_a@@. In fact, it turns out that each term evaluates to @@\pm \pi@@ depending on the sign of @@\Re[r_a]@@. To actually evaluate the integral, Claude suggests decomposing @@r_a = x_a + iy_a@@, then using the fact that
%% \frac{1}{a + ib} = \frac{a - ib}{a^2 + b^2} %%
for @@a,b \in \RR@@. Doing so gives
%% \begin{align*} \Delta \arg \left[ \gamma_a \right] &= \Im \left[ \int_{-\infty}^{\infty} \frac{i}{it - r_a} dt \right] \nl &= \Im \left[ \int_{-\infty}^{\infty} \frac{i}{i(t - y_a) - x_a} dt \right] \nl &= \Im \left[ \int_{-\infty}^{\infty} \frac{i}{it - x_a} dt \right] \nl &= \Im \left[ \int_{-\infty}^{\infty} \frac{1}{t + ix_a} dt \right] \nl &= \Im \left[ \int_{-\infty}^{\infty} \frac{t - ix_a}{t^2 + x_a^2} dt \right] \nl &= -x_a \int_{-\infty}^{\infty} \frac{1}{t^2 + x_a^2} dt. \end{align*} %%
Finally, substituting @@t = |x_a| \sinh u@@ and @@dt = |x_a| \cosh u \, du@@ gives
%% \begin{align*} \Delta \arg \left[ \gamma_a \right] &= -\frac{x_a \cdot |x_a|}{x_a^2} \int_{-\infty}^{\infty} \frac{\cosh u}{\sinh^2 u + 1} du \nl &= -\sign(x_a) \int_{-\infty}^{\infty} \frac{1}{\cosh u} du \nl &= -\sign(x_a) \cdot \pi. \end{align*} %%
This is exactly what we got for each term with the informal proof, just written a bit differently. Note that if we had substituted @@t = x_a \sinh u@@ instead, we may have had to swap the limits on the integral depending on the sign of @@x_a@@. That gives the same result, though.
Observations
A few noteworthy corollaries follow from the Routh-Hurwitz theorem. First, the degree of the polynomial @@n@@ is how many roots it has, which is just the sum @@n_L + n_R@@. It follows that @@n_L - n_R@@ has the same parity as @@n@@.4 As a result, the winding number of @@\gamma@@ will be an integer for even degree polynomials, and a half-integer otherwise. Furthermore, we know the behavior of @@\gamma@@ in the "far-field", where the leading term of @@p@@ dominates. Assuming @@p@@ is monic for simplicity, for even degree,
%% \begin{align*} p(-i \cdot \infty) &\approx (-i \cdot \infty)^{2k} = (-1)^k \cdot \infty \nl p(+i \cdot \infty) &\approx (+i \cdot \infty)^{2k} = (-1)^k \cdot \infty, \end{align*} %%
and for odd degree
%% \begin{align*} p(-i \cdot \infty) &\approx (-i \cdot \infty)^{2k+1} = (-1)^k \cdot -i \cdot \infty \nl p(+i \cdot \infty) &\approx (+i \cdot \infty)^{2k+1} = (-1)^k \cdot +i \cdot \infty. \end{align*} %%
56 Combining this with the earlier observation, we can qualitatively describe @@\gamma@@:
- When @@n@@ is even, @@\gamma@@ will enter from either side along the real axis, and exit along the real axis on the same side it came from.
- When @@n@@ is odd, @@\gamma@@ will enter from either side along the imaginary axis, and exit along the imaginary axis from the opposite side it came from.
The winding number is a further constraint on top of this, though this description already forces the winding number to be an integer or a half-integer when @@n@@ is even or odd respectively.
Cauchy Index Formulation
Sometimes, the Routh-Hurwitz theorem is written in terms of Cauchy indices. How this rewrite is done was initially quite mysterious to me. It started to become clear once I realized that, if @@p(z) = \sum_{a=0}^n k_a z^a@@ has real coefficients1, then we can split into the even and odd terms to get
%% \begin{align*} p(it) &= \sum_{a=0}^n k_a (it)^a = \sum_{a=0}^n k_a i^a t^a \nl &= \sum_{a = 2b} k_a (-t^2)^b + it \sum_{a = 2b+1} k_a (-t^2)^b \nl &= p_e(-t^2) + it \cdot p_o(-t^2). \end{align*} %%
The upshot is that the real and imaginary parts of this polynomial path are themselves given by polynomials. Specifically, @@p_e@@ and @@p_o@@ are polynomials with the even and odd coefficients of @@p@@ respectively. They have degree at most @@\lfloor \frac{n}{2} \rfloor@@ and @@\lfloor \frac{n-1}{2} \rfloor@@ respectively. We let7
%% \begin{align*} p_r(t) &= \Re[p(it)] = p_e(-t^2) \nl p_i(t) &= \Im[p(it)] = t \cdot p_o(-t^2). \end{align*} %%
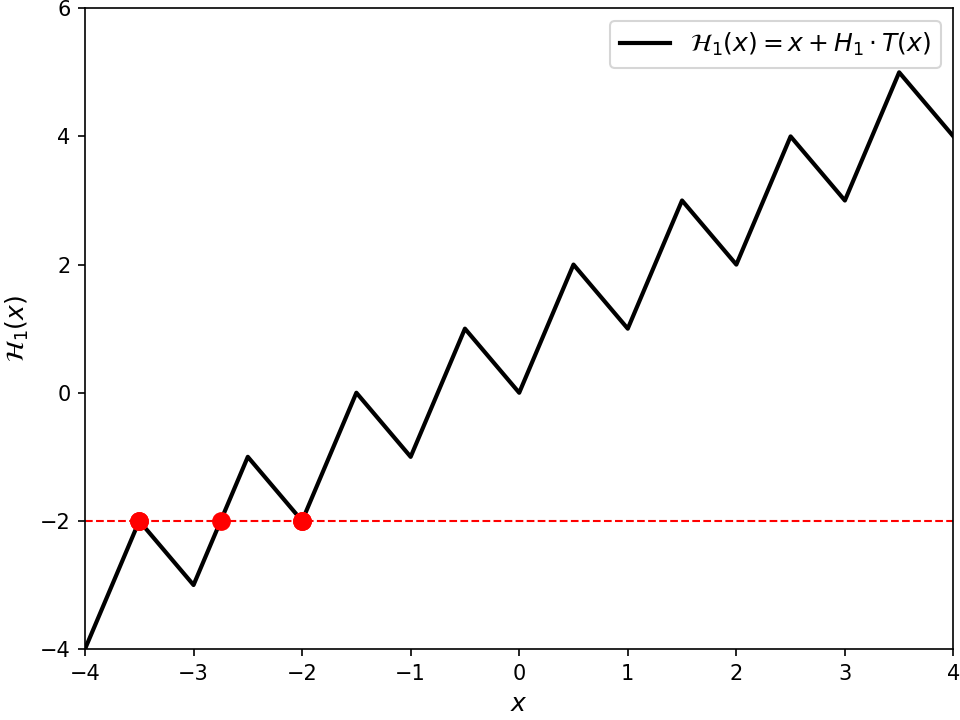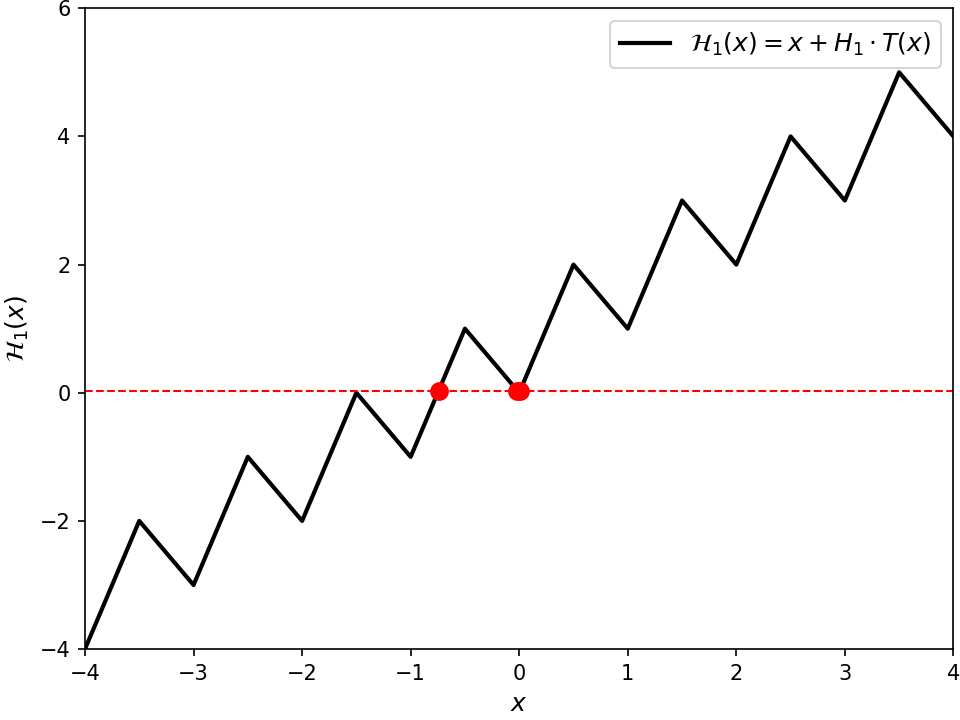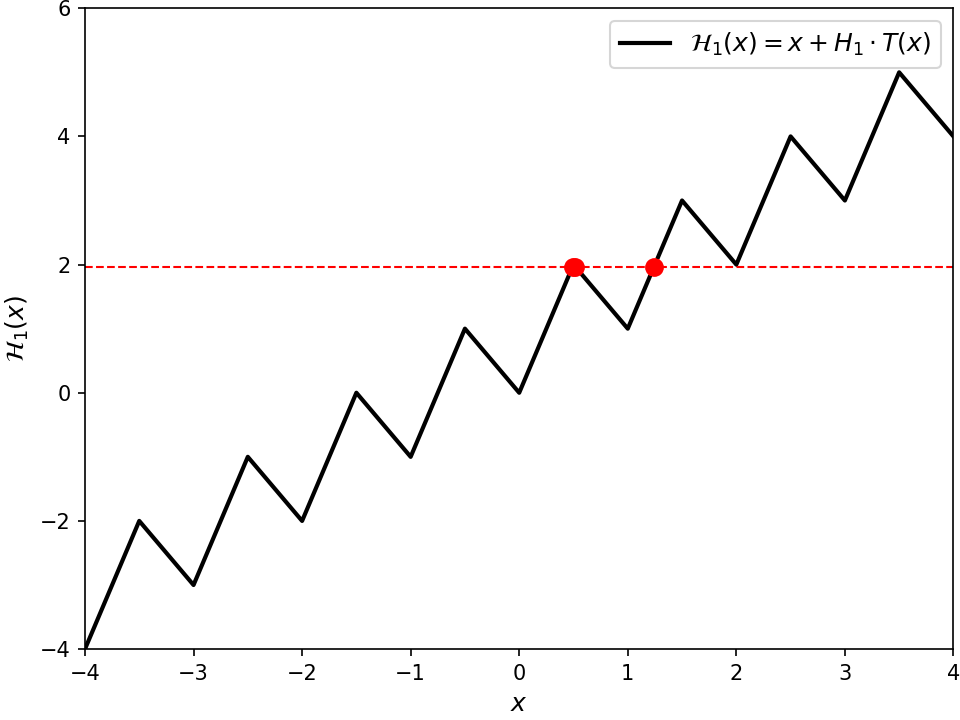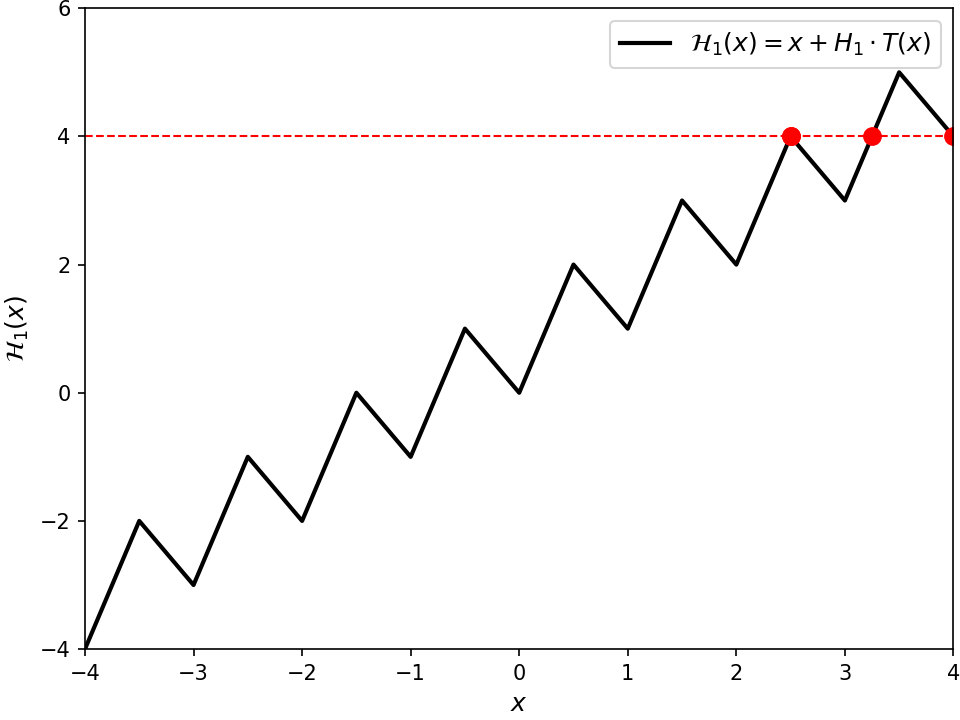
For now, let's say @@p@@ has even degree. In that case, there is an elegant way to think about the Cauchy index @@I_{-\infty}^\infty \frac{p_i(t)}{p_r(t)}@@.
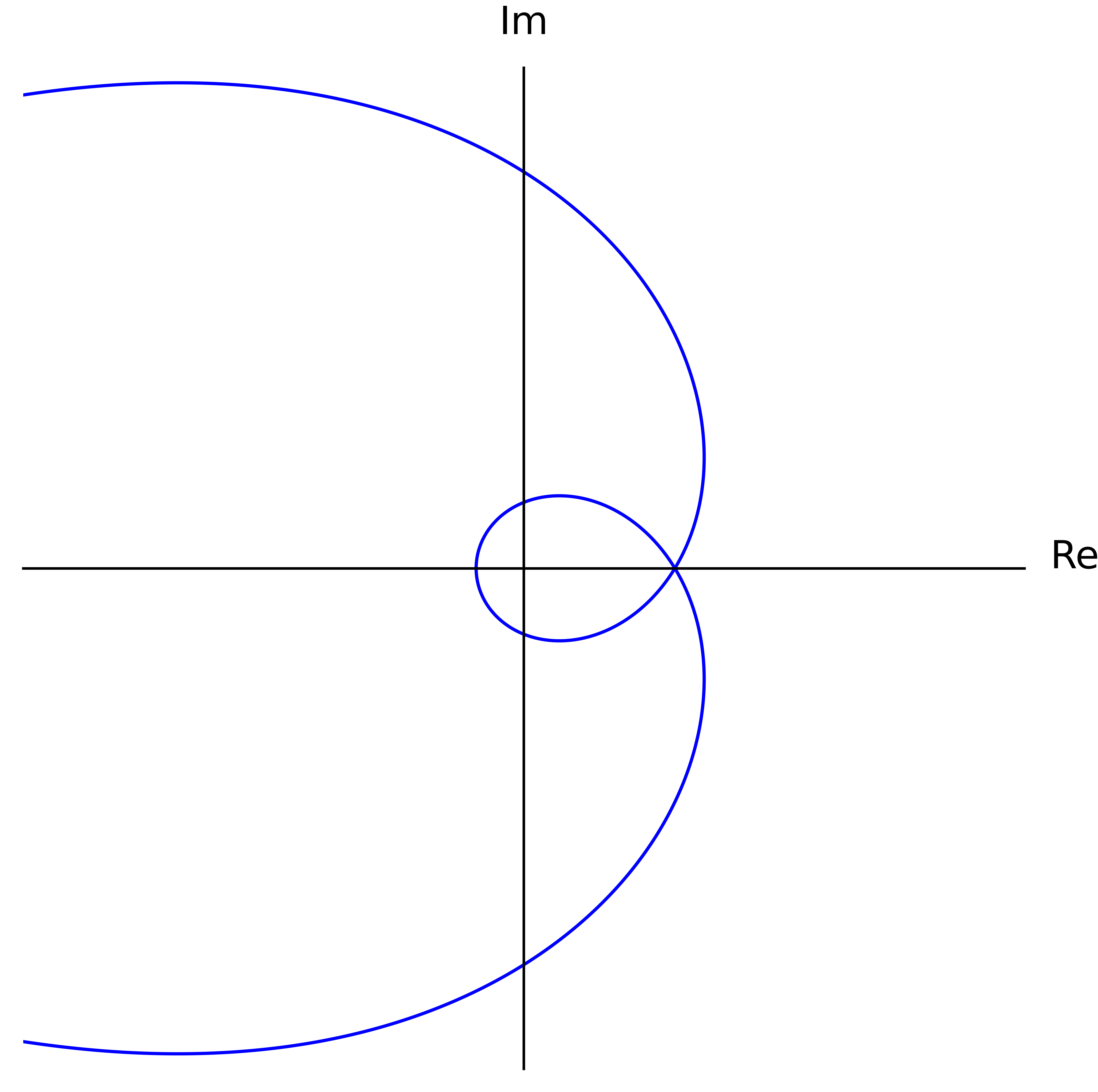
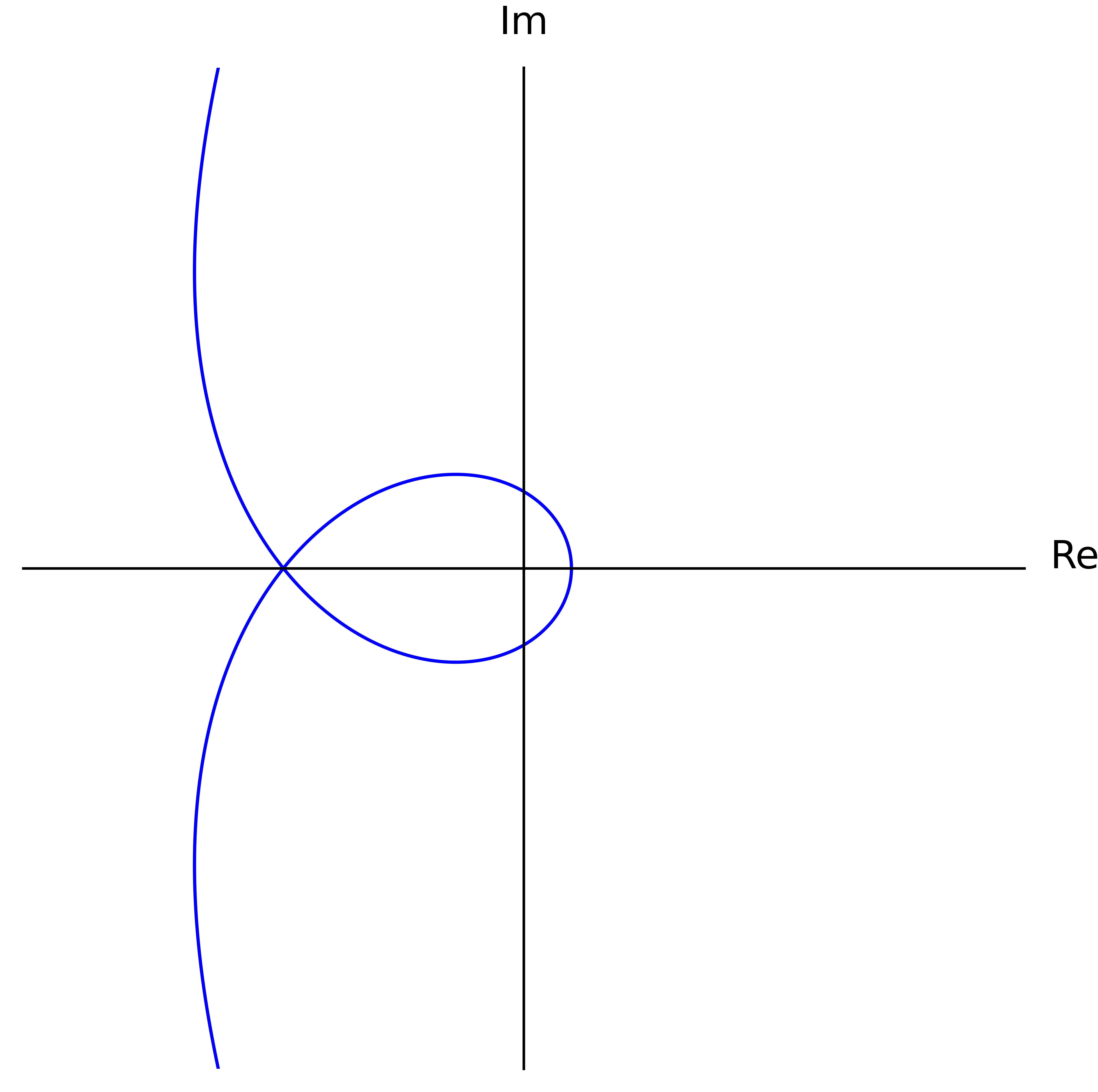
For the uninitiated, the Cauchy index of some rational function over a real interval is computed by summing over all of its poles — that is, every @@s@@ where its denominator is zero — in that interval. We only consider poles where the denominator @@p_r@@ changes sign. If it doesn't, then that pole just contributes @@0@@ to the sum. If it does change sign at @@s@@, then the numerator @@p_i(s)@@ will be either positive or negative.8 Combining those effects, overall the rational function @@\frac{p_i(t)}{p_r(t)}@@ will change sign at @@s@@ through a vertical asymptote. If it changes from negative to positive, then @@s@@ contributes @@+1@@. If from positive to negative, @@-1@@. Wikipedia has a good example computation.

In our case for @@I_{-\infty}^\infty \frac{p_i(t)}{p_r(t)}@@, the poles considered by the Cauchy index correspond to the values of @@t@@ where @@\gamma@@ crosses the imaginary axis. In other words, it captures when @@\gamma@@ changes which side of the complex plane it's on — either the left or the right half. When we change sides, we can pass the origin either clockwise or counterclockwise. This "rotation information" is what's tracked by the Cauchy index, as shown in the figure above. Transitioning counterclockwise contributes @@-1@@ to the sum since @@\frac{p_i(t)}{p_r(t)}@@ goes from positive to negative at that value of @@t@@. Likewise, transitioning clockwise contributes @@+1@@. Now it turns out, this rotation information at each side-change is sufficient to compute the final winding number. In the end, each counterclockwise transition contributes @@+\frac{1}{2}@@, and each clockwise @@-\frac{1}{2}@@. For example, suppose @@\gamma@@ happens to come in from the left, then pass under the origin (counterclockwise). If no further transitions were to happen9, @@\gamma@@ would have to exit along the positive real axis, and the final winding number would be forced to be @@+\frac{1}{2}@@. If instead the path continued by passing above the origin (counterclockwise), then it would be forced to exit along the negative real axis assuming no further transitions, and the final winding number would be @@+\frac{2}{2}@@. Similarly if instead it then passed under the origin (clockwise), then again it would be forced to exit left, but this time with a final winding number of zero. Ultimately, we can get away with only looking at the side transitions since @@\gamma@@ can only enter and exit along the real axis.
To summarize, all counterclockwise passes contribute @@+\frac{1}{2}@@ to the winding number and @@-1@@ to the Cauchy index, while all clockwise passes count for @@-\frac{1}{2}@@ and @@+1@@ respectively. Taking care of the signs, we have
%% \begin{align*} \frac{1}{2\pi} \Delta \arg \left[ \gamma \right] = \frac{1}{2}(n_L-n_R) &= -\frac{1}{2} \cdot I_{-\infty}^\infty {\textstyle \frac{p_i(t)}{p_r(t)}} \nl n_L - n_R &= -I_{-\infty}^\infty {\textstyle \frac{p_i(t)}{p_r(t)}}. \end{align*} %%
This formula only works for even degree polynomials. For odd degree polynomials, the logic is the same, but we're looking at transitions between the top and bottom halves of the complex plane. Since these transitions happen where the imaginary part is zero, the end result is related to the Cauchy index of @@\frac{p_r(t)}{p_i(t)}@@ instead. In the end,
%% n_L - n_R = \begin{cases} -I_{-\infty}^\infty {\textstyle \frac{p_i(t)}{p_r(t)}} & \text{if $n$ is even} \nl +I_{-\infty}^\infty {\textstyle \frac{p_r(t)}{p_i(t)}} & \text{if $n$ is odd} \nl \end{cases}. %%

Eve's Theorem
With all the groundwork we've laid so far, the proof of Eve's theorem is mostly straightforward, though there is also a creative technique it uses to increase its strength. In short, Eve's theorem says that if almost all of the roots of some polynomial @@p@@ lie on one half of the complex plane — either the left or the right half, then all the roots of @@p_o@@ are real. The original proof uses the properties of Cauchy indices to prove this, but I find it more instructive to think of it in terms of the path @@\gamma(t) = p(it)@@.
First though, we can perform a few simplifications. Without loss of generality, let's assume most of the roots are on the left side, with real part at most zero. If that's not the case, we can instead run this argument on @@q(z) := p(-z)@@. This has the effect of swapping the sides of each of the roots. But note that
%% p(-z) = p_e(z^2) - z \cdot p_o(z^2), %%
so @@q_e(z) = p_e(z)@@ and @@q_o(z) = -p_o(z)@@. Since this argument shows that all the roots of @@q_o@@ are real, it follows that all the roots of @@p_o@@ are as well. Without loss of generality, we may also assume that no roots are on the imaginary axis. The Routh-Hurwitz theorem doesn't handle that case, but Eve's theorem does. If @@p(iy) = 0@@ for some @@y@@, then @@-y^2@@ is a common root of @@p_e@@ and @@p_o@@; remember how we decomposed @@p(it)@@ earlier. So, we can just factor that root out before proceeding with this argument.
"Weak" Version
For now, assume all @@n@@ roots of @@p@@ are in the left half of the complex plane. The full version of Eve's theorem weakens this requirement slightly, making it stronger overall, but a lot of the proof ideas carry over. Regardless, by the Routh-Hurwitz theorem, the winding number of @@\gamma@@ about the origin is @@+\frac{n}{2}@@. We're going to use that winding number to lower-bound how many real roots @@p_i@@ and thus @@p_o@@ have, ultimately showing all of @@p_o@@'s roots are real.
Consider the case where @@n@@ is even. In order to get the winding number as high as @@+\frac{n}{2}@@, @@\gamma@@ must cross the imaginary axis counterclockwise at least @@n@@ times, using the ideas from the previous section. And in fact, those crossings must be the only ones, since @@p_r@@ has at most @@n@@ real roots because of the bounds on its degree. Finally, since those crossings of the imaginary axis have to alternate above and below the origin (just look at the figure), @@\gamma@@ must cross the real axis at least @@n-1@@ times between them (by fencepost). This gives @@\Im[\gamma(t)] = p_i(t)@@ at least @@n-1@@ real roots. And this is also exact since the degree of @@p_i@@ for even @@n@@ is at most @@n-1@@.
Ignoring the extra root at zero, the roots of @@p_i@@ form @@\frac{1}{2}(n-2)@@ positive/negative root pairs, since @@\frac{1}{z} p_i(z)@@ is even.10 Hence, we can write
%% \begin{align*} p_i(z) &= z \cdot \prod_{a = 1}^{\frac{1}{2}(n-2)} (z + r_a)(z - r_a) \nl &= z \cdot \prod_{a = 1}^{\frac{1}{2}(n-2)} (z^2 - r_a^2) \nl &= z \cdot \prod_{a = 1}^{\frac{1}{2}(n-2)} -((-z^2) + r_a^2). \end{align*} %%
Pattern matching gives
%% p_o(z) = \prod_{a = 1}^{\frac{1}{2}(n-2)} -(z + r_a^2), %%
so @@p_o@@ has @@\frac{1}{2}(n-2)@@ real roots, at @@-r_a^2@@ for each @@a@@. Finally, since the degree of @@p_o@@ is at most @@\frac{1}{2}(n-2)@@ when @@n@@ is even, we conclude that all the roots of @@p_o@@ are real.
The case for @@n@@ odd is analogous and in some respects even easier. Here, @@p_i@@ has at exactly @@n@@ real roots due to the winding number forcing that many crossings of the real axis. Ignoring the extra root at zero, we get @@\frac{1}{2}(n-1)@@ root pairs. Those give rise to @@\frac{1}{2}(n-1)@@ real roots in @@p_o@@, which accounts for all of them.
In the presence of stronger assumptions on the roots than what the full version makes, we seem to actually have proven a statement stronger than what's given in the consequent of Eve's theorem. First, we seem to have shown that all the roots of @@p_o@@ are non-positive real numbers. Furthermore, our analysis of @@\gamma@@ additionally showed that the real roots of @@p_i@@ are all distinct, since @@\gamma@@ must physically cross the real axis @@n-1@@ times. Propagating this through seems to show that all the roots of @@p_o@@ are distinct too, since the root pair @@\pm r_a@@ only shows up once in @@p_i@@'s factorization.
Full Version
The actual formulation of Eve's theorem says something stronger: it also allows a single root to be in the right half of the complex plane, while the remaining @@n-1@@ roots stay in the left half. This makes @@\gamma@@'s winding number @@\frac{1}{2}(n-2)@@.
For even @@n@@, analyzing @@\gamma@@ the same way as in the last section, we only guarantee @@n-2@@ crossings and at least @@n-3@@ real roots for @@p_i@@ between them. Miraculously, this is still enough to show that all the roots of @@p_o@@ are real. To see this, observe that if @@p_i(r) = 0@@, then the same is true for @@r^*@@, @@-r@@, and @@-r^*@@. If @@p_i@@ had a complex root — one that's not on the real nor imaginary axes, then all four of these numbers would be distinct. Combining them with the @@n-3@@ real roots we already have, we'd get @@n+1@@ roots in total, which is impossible since @@p_i@@ has degree at most @@n@@. Therefore, all of @@p_i@@'s roots are either real or purely imaginary. That means the square of each of its roots is a real number, so we can repeat the process from the last section to get
%% p_o(z) = \prod_{a = 1}^{\frac{1}{2}(n-2)} -(z + r_a^2). %%
Here, each of @@p_o@@'s @@\frac{1}{2}(n-2)@@ roots @@-r_a^2@@ are real, though they're not necessarily non-positive.
When @@n@@ is odd, we similarly conclude @@p_i@@ has at least @@n-2@@ real roots, at which point the same argument in the last paragraph allows us to conclude that all the roots of @@p_o@@ are real.
Application to Knuth's Algorithm
Finally, we arrive at the algorithm that motivated this entire exploration. We'll consider a polynomial @@p : \RR \to \RR@@. We want to make an algorithm that evaluates @@p@@ at an arbitrary @@x \in \RR@@ using as few real-number operations as possible. Knuth's approach to this problem is to split
%% p(x) = p_e(x^2) + x \cdot p_o(x^2). %%
Now suppose @@p_o@@ has a real root @@r@@. Then we can factor it out of @@p_o@@, and we can divide it out of @@p_e@@ to get a real number as a remainder. In the end,
%% \begin{align*} p_o(x) &= (x - r) \cdot q_o(x) \nl p_e(x) &= (x - r) \cdot q_e(x) + c, \end{align*} %%
so
%% \begin{align*} p(x) &= (x^2 - r) \cdot q_e(x^2) + c + x \cdot (x^2 - r) \cdot q_o(x^2) \nl &= (x^2 - r) \cdot \left( q_e(x^2) + x \cdot q_o(x^2) \right) + c \nl &= (x^2 - r) \cdot q(x) + c. \end{align*} %%
We can apply this approach recursively to @@q@@ to get an algorithm for evaluating @@p(x)@@. And it's a great algorithm! Assuming we precompute @@x^2@@, each recursive step to reduce the degree of @@p@@ by two requires two additions and just one multiplication. In total, to evaluate a polynomial of degree @@n@@, we need @@n+O(1)@@ additions and @@\frac{1}{2}n+O(1)@@ multiplications, which is the best possible.
Sadly, running this algorithm to completion requires all the roots of @@p_o@@ to be real. We could try to allow @@r@@ to be complex. Unfortunately, then the algorithm starts requiring complex additions and multiplications, which are twice and four times as expensive as the corresponding real operations respectively, and the advantage of Knuth's algorithm fizzles out.
Luckily, we have Eve's theorem, which sometimes guarantees that all the roots of @@p_o@@ are real. Furthermore, given an arbitrary polynomial @@p@@, we can "preprocess" it to satisfy the premises of the theorem. Specifically, we can shift most of its roots to the left half of the complex plane by constructing @@q(x) := p(x + s)@@ for some sufficiently large @@s@@. We can then run Knuth's algorithm to evaluate @@q@@ at @@x - s@@, giving @@p(x)@@.
-
We'll assume that all polynomials have real coefficients. Unless otherwise stated, we'll also assume all polynomials map @@\CC \to \CC@@. ↩ ↩2 ↩3
-
This is not entirely accurate. The "meat" of the theorem concerns relating this difference to some generalized Sturm chain. But we don't need that part of the theorem here. ↩
-
Note that since @@\gamma@@ is not closed, the "winding number" need not be an integer. ↩
-
More explicitly, this is because @@-1 \equiv 1 \mod 2@@. ↩
-
If @@p@@ is not monic, the signs of all of these expressions will change according to the sign of the leading coefficient, but they all change in the same way. ↩
-
This abuses notation slightly. Really, just take @@\infty@@ to be some very large positive number. ↩
-
Different authors write this real/imaginary split in different ways. For instance, Wikipedia defines @@P_0@@ to be what I would call @@p_r@@, and @@P_1@@ to be @@p_i@@. ↩
-
We never run into the case where the numerator and the denominator of the rational function are simultaneously zero. That's because we assume @@p@@ has no roots on the imaginary axis. To calculate the Cauchy index in that case, we divide out the common factor before proceeding. ↩
-
It can't since it must exit the same way it came, but I'm using this to demonstrate a point. ↩
-
Strictly speaking, I also need to show that this evenness is preserved when we deflate @@\frac{1}{z} p_i(z)@@ by dividing out a root pair. It is, since @@(z+r)(z-r) = (z^2 - r^2)@@ is even. But, I'm just going to take this as a known fact. ↩